
We've recently completed a critical engineering milestone at Noah: migrating our internal ledger system from AWS QLDB to Amazon Aurora PostgreSQL. The transition became necessary following AWS's announcement to deprecate QLDB by July 2025.
We designed a new ledger system focused on speed, accuracy, and long-term scalability across products, while still providing an immutable and verifiable history of records over time. As part of this effort, we executed our largest migration to date, transferring millions of records across multiple tables to our new PostgreSQL database. The migration was performed without any downtime and with no impact on end users.
Building the Postgres-Based Ledger System
We selected Aurora PostgreSQL Serverless for its strong ACID compliance and transactional consistency, which are critical foundations for a reliable, ledger-grade system. In addition to ensuring data integrity, it offers the flexibility to scale seamlessly with demand and optimize operational costs, providing the performance we need without sacrificing efficiency.
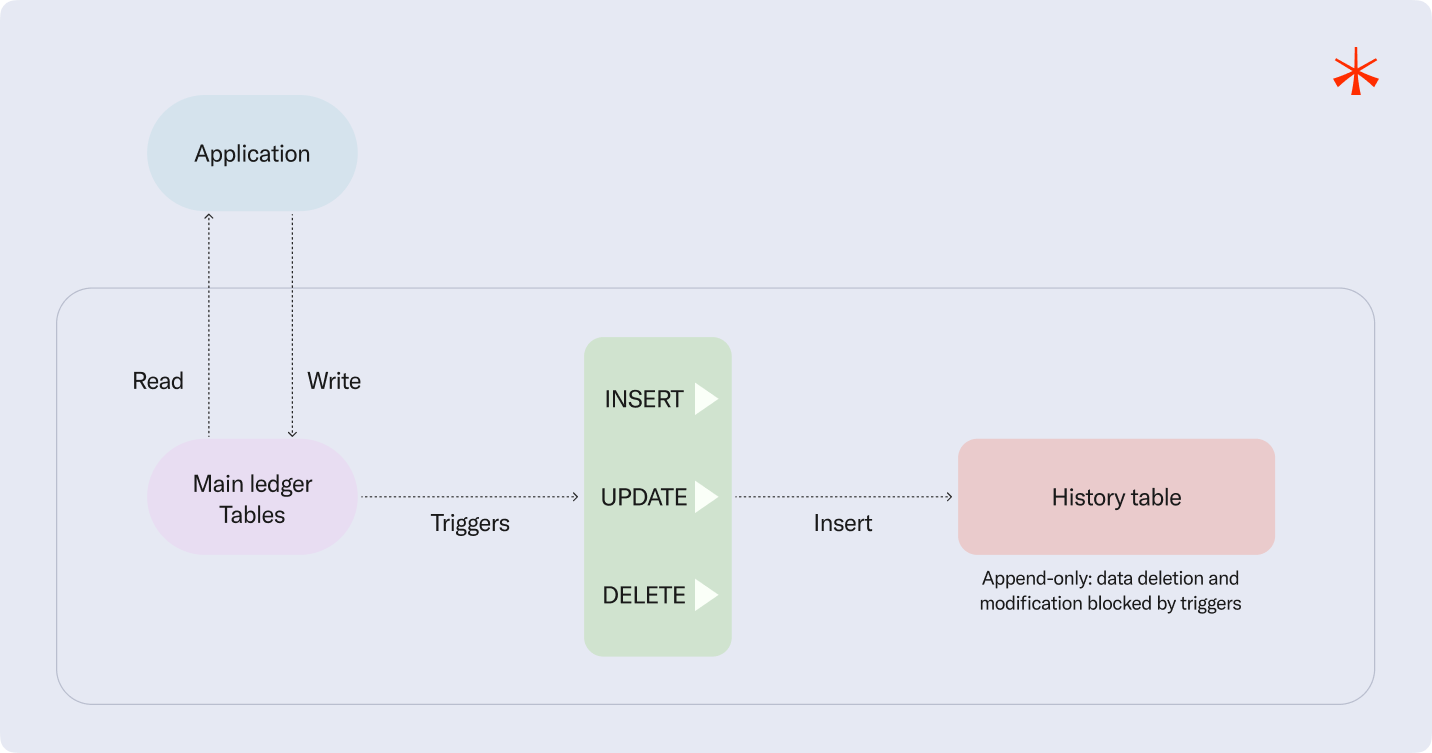
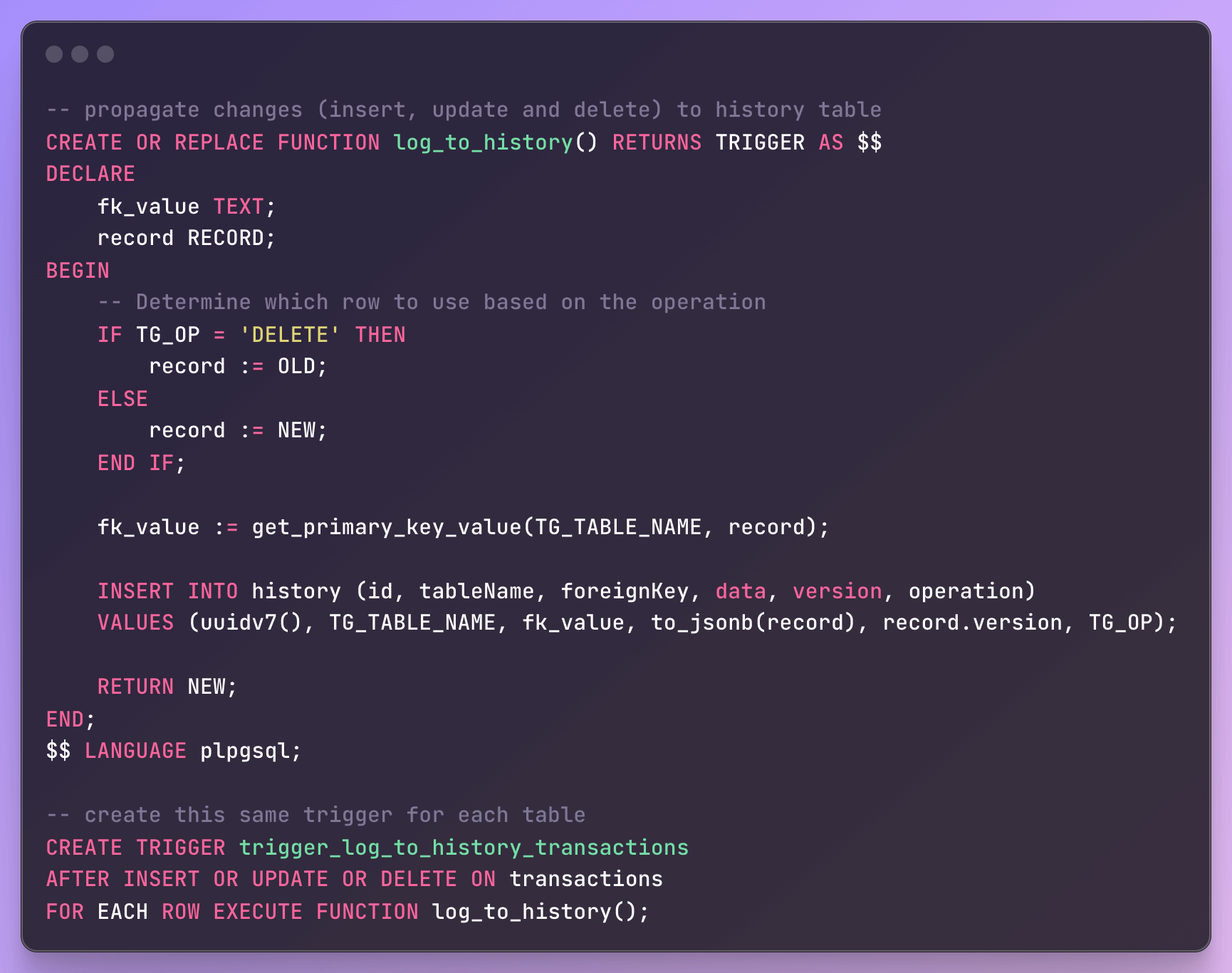
To replicate the guarantees previously offered by QLDB, we designed a Postgres-based solution that preserves the original append-only model through a dedicated history table. This table captures every state transition for each record, ensuring that all data changes are recorded immutably. We achieved this by using PostgreSQL triggers to automatically propagate all write operations such as inserts, updates, and deletions to the history table, which has its own guardrails to prohibit data modification and deletion, ensuring a complete audit trail.
To maintain our system’s event-driven architecture and support downstream consumers, we implemented a ledger stream replication pipeline. Changes captured on Postgres are streamed to PubSub systems, preserving compatibility with our existing integrations and workflows.
Together, these components allow us to emulate QLDB’s audit trail and real-time streaming features on top of a relational database system, combining the integrity of a ledger with the operational benefits of PostgreSQL.
The Four-Phase Migration Strategy
In order to minimize the risk associated with migrating critical data, ensure a seamless transition with zero downtime, and gain confidence in the new infrastructure through a complete and interactive end-to-end validation, we chose to implement a dual-write migration strategy. This approach allowed us to write data to both the legacy and new systems in parallel, giving us the ability to monitor consistency, validate behavior under real-world conditions, and switch over only once we were fully satisfied with the results.
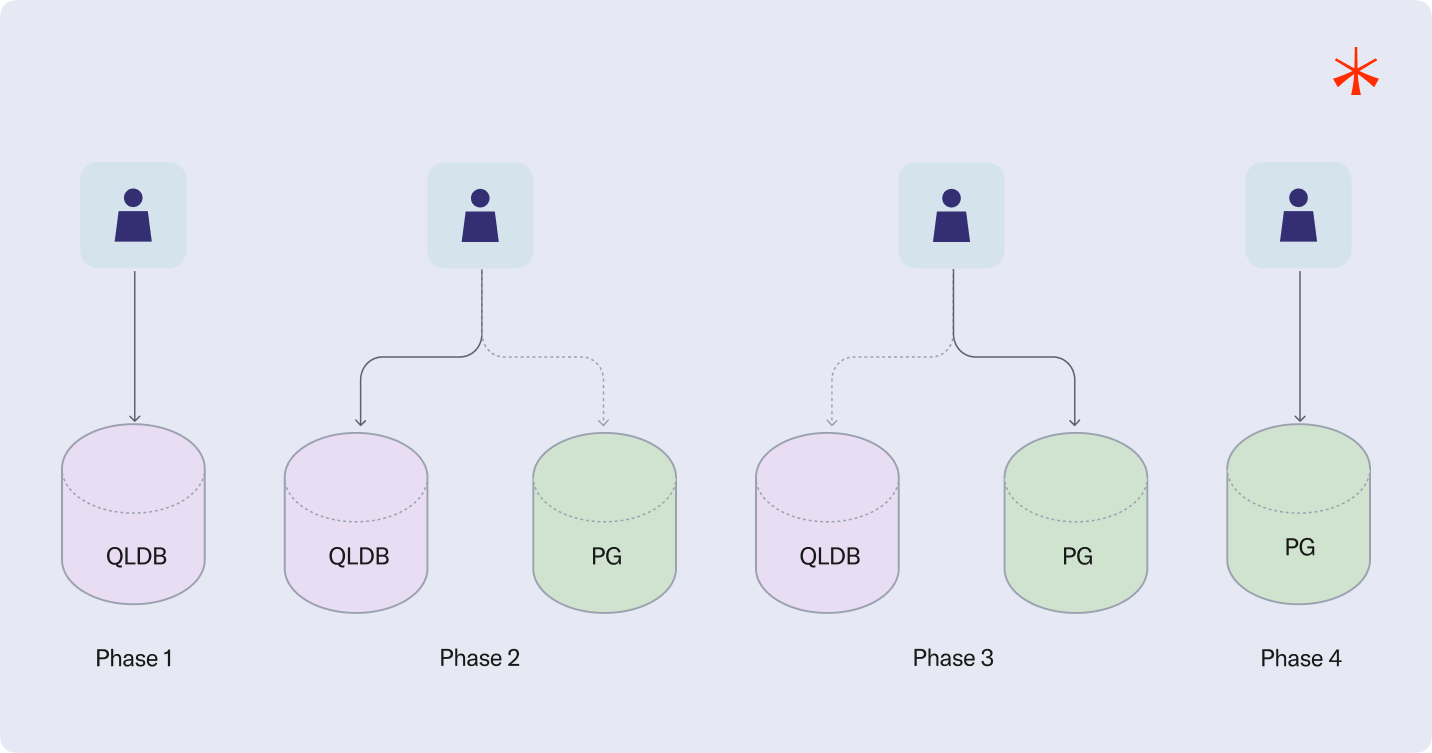
Phase 1 represents the pre-migration state, where the whole system relied on QLDB as ledger. In Phase 2, we introduce the Postgres ledger and begin dual-writing to both ledgers and also reading from both in order to log discrepancies between them. At this point in time Postgres writes and reads were heavily guarded meaning that if any error happened it was safely logged and ignored in order not to disrupt the whole operation, we called it best-effort writes and reads. This was by far the most important phase of the migration, this was the phase in which we actually backfilled the records, this was an iterative process of validation and incremental adjustments until we built up the confidence needed to advance to the next phase. In Phase 3, after thoroughly validating and battle testing the Postgres integration, we promoted it to become the primary ledger. We still kept QLDB around and could switch back to it if needed. We were particularly careful during this phase to ensure that no database events were missed in the stream pipeline. To achieve this, we used a combination of feature flags and timestamps to intentionally introduce a brief overlap period with duplicated events immediately following the cutover. Ahead of that, we ensured that all event consumers were capable of idempotently handling duplicate events, allowing the transition to proceed safely without data loss or inconsistencies. Finally, after some last validations we fully decommissioned QLDB and finished the migration (Phase 4).
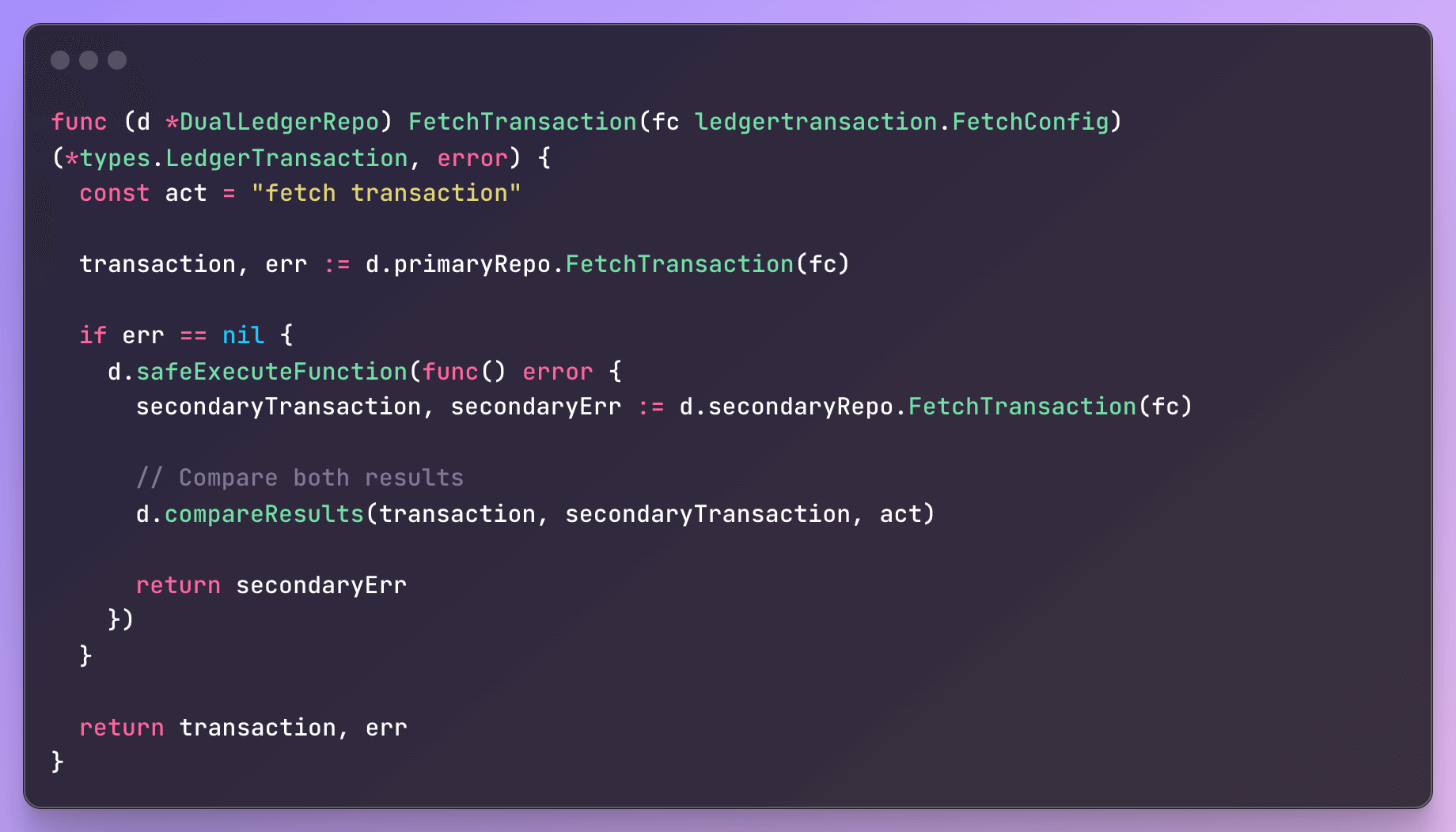
To enable this migration strategy, we implemented three versions of the same Ledger interface: QldbLedger, PostgresLedger, and DualLedger. The whole codebase interacted exclusively with DualLedger, which acted as a middle management layer responsible for orchestrating behavior across the two ledgers. It leveraged feature flags to determine which ledgers were enabled and which one was currently designated as the primary. Based on this configuration, it routed operations to both systems, compared the results, and enforced guardrails to ensure that any inconsistencies or failures in the secondary ledger would not impact the integrity or availability of the primary system.

Ensuring Data Consistency: Triple Comparison
Throughout the migration, we relied on a comprehensive validation strategy to ensure data consistency between QLDB and Postgres. This involved three complementary methods of comparison, each targeting a different aspect of data integrity.
Read comparison: we implemented this validation by issuing queries to both ledgers, verifying that responses matched across systems using go-cmp. This approach allowed us to detect discrepancies during live application interactions, giving immediate feedback on whether the new system was behaving as expected.
Stream validation: Each ledger maintained its own streaming pipeline, yet the events streamed should be identical. To verify this, we developed a temporary Lambda function that consumed events from both pipelines in real time. This function matched corresponding events across the two streams, allowing us to identify any discrepancies in payloads. It also surfaced missing events on either side, helping us catch propagation gaps or processing delays early in the migration process.
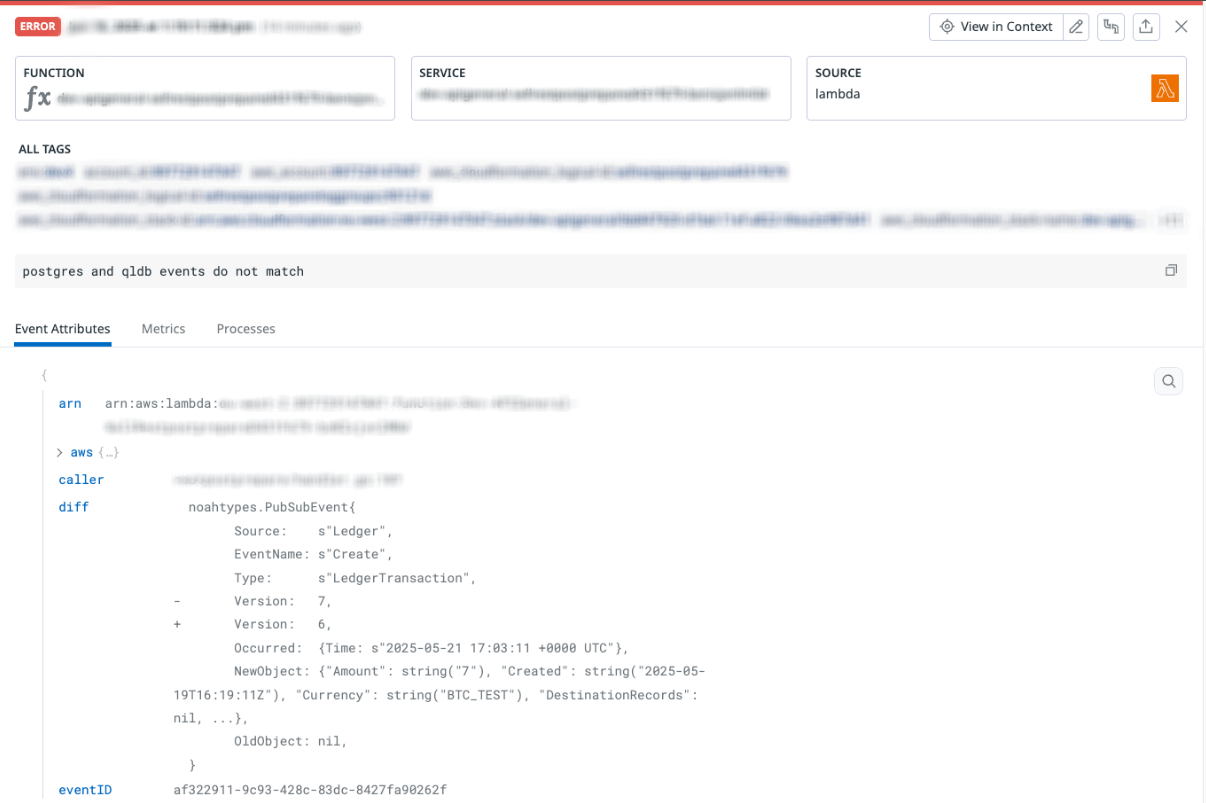
Active scan: Since this method was more resource-intensive, we used it sparingly to avoid unnecessary load. However, during critical phases of the migration, we performed full-table scans on one ledger and validated that every record had a matching and identical counterpart in the other.
Together, these validation layers gave us a high degree of confidence at every stage of the migration. They enabled us to detect data drift early, investigate root causes, and resolve issues before they could impact production workflows.
Lessons Learned
While technically complex, this migration offered several valuable insights:
- A repeatable backfill process is essential when executing migrations at this scale. The process revolves around iterative rounds of validation and incremental adjustments. Throughout the migration, we encountered several challenges, including backfill rate limiting, data incompatibilities with the new schema, and cases where the ledgers began to drift apart. Being able to reliably backfill data through a simple and repeatable process allowed us to address these issues quickly and ultimately proved to be one of the key factors in the success of the migration.
- Verifying data consistency is essential in any migration and should be approached with a layered and automated strategy wherever possible. Doing so is critical for establishing confidence in the integrity of the new system and is a key factor in determining when it is safe to progress to the next phases of the migration.
- Time-based cutover is definitely something that we didn’t plan from the beginning but introducing a scheduled switchover mechanism proved to be critically important. Initially, we relied on boolean feature flags to determine the primary ledger, but this led to inconsistencies across components, as different parts of the system occasionally had conflicting views of which ledger was active due to caching and the deployment strategy of those feature flags. These mismatches resulted in errors during the early phases of the migration. To resolve this, we transitioned to using future-dated timestamps AppConfig to coordinate the switch. This allowed us to perform a fully atomic cutover, ensuring that all services agreed on the active ledger at the exact same point in time.
- Feature flags for operational agility: Using feature flags gave us the flexibility and control to dynamically manage key configuration states, such as enabling or disabling specific components and defining which ledger should act as the primary. This setup eliminated the need for code changes or redeployments when adjusting these behaviors. It greatly improved our ability to iterate, test, and adapt system behavior in real time. Additionally, it helped us separate infrastructure rollouts from application logic, making the migration process more resilient and easier to reverse.